Cloud computing has become nowadays one of the most popular practices, but it doesn't have to be limited only to a reduced group of specialists. In fact, I'll show you how to take advantage of this new thing called "serverless" on AWS to host a static website
The idea behind this is not to worry about the underlying infrastructure, AWS will handle that. In this case, we'll start by using one of the oldest services they provide, Amazon S3.
Accessing Amazon AWS
If you are new to Amazon AWS, you should start by creating a new account and use the free 1 year trial, which allows a lot of room for playing with it.
In this example I show a real domain I already own and a simple HTML file (very simple)
Creating the S3 bucket
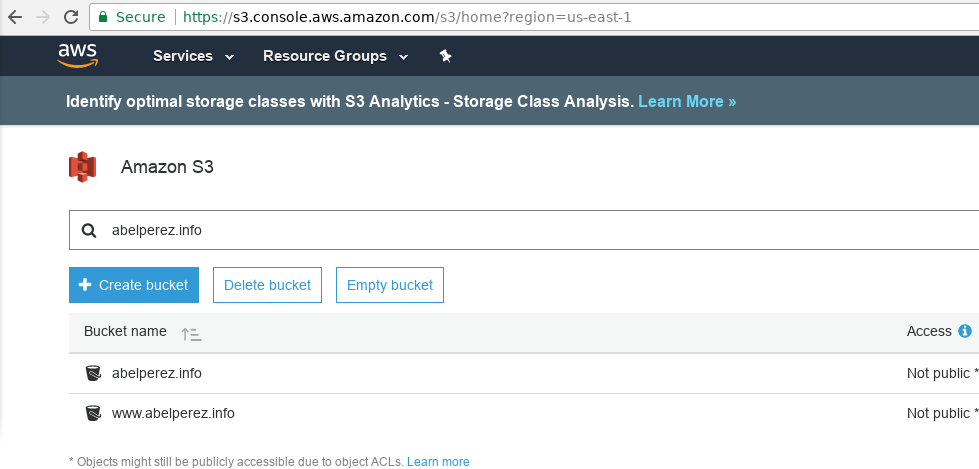
Once you've logged in AWS console, choose Services from the top left menu, then S3 in Storage category or just browse to https://s3.console.aws.amazon.com/s3/
Click on Create Bucket and follow the wizard. It's important to note that if you're trying to use your own domain name within AWS (using Route 53) the name of your bucket has to match the domain name. In this case I'm using www.abelperez.info, therefore, that's my bucket name. Also, if you plan to use a CDN (using CloundFront distribution), this is not relevant, however I encourage this practice as it will organise better the buckets for their purpose. For more information about how to create a bucket, see here
Your S3 console should look similar to this
Converting the S3 bucket in a website
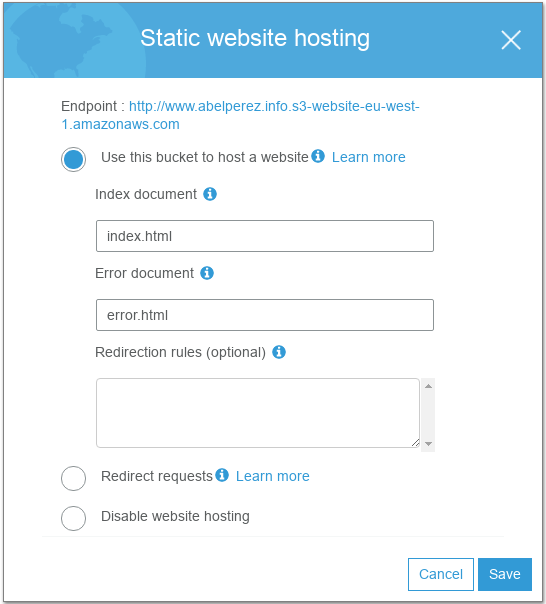
Next step, on the same console page, select the bucket and click on Properties, then find Static website hosting. In the expanded form, choose the option Use this bucket to host a website and specify index and error documents accordingly, typically the same as proposed by the watermark. Save and take not that the format of your HTTP endpoint (public url) is like http://www.abelperez.info.s3-website-eu-west-1.amazonaws.com
It follows the convention of http://<your-bucket-name>.s3-website-<region-where-it-was-created>.amazonaws.com
It should look like this
Granting public read access to all files
Granting public read to all objects is usually deemed as a bad practice, but in this particular case (and for now), we need a way to make public all files we upload to the bucket. S3 Buckets allow a very granular permission system on all objects inside a bucket, that means every time we upload a file, we are responsible for choosing the right permissions. However, this process can be tedious and prone to error (it's easy to forget)
Let's add a Bucket Policy that will entitle all clients request to read the objects inside our bucket. To do that, select the bucket in the console and click on Permissions tab, then click on Bucket Policy and add the following text, just replacing www.abelperez.info with your bucket name
{
"Version": "2012-10-17",
"Id": "PublicReadAccess",
"Statement": [
{
"Sid": "GrantPublcReadAccess",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::www.abelperez.info/*"
}
]
}
Creating AWS policies is out of the scope of this post, but basically it allows the GetObject action to all objects inside the bucket named www.abelperez.info
Finally, upload some files
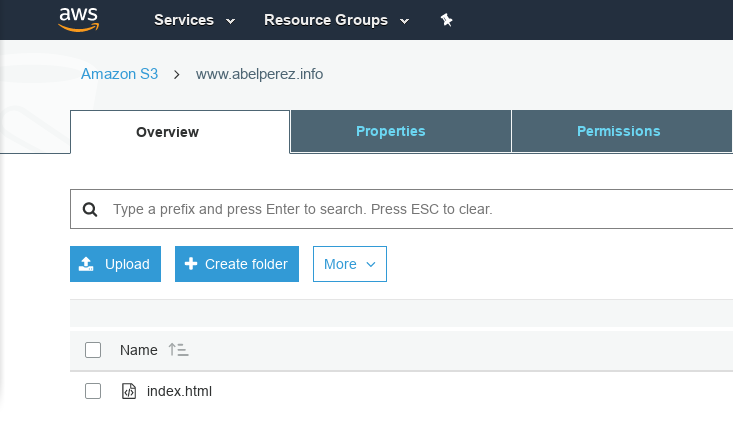
Just for demonstration purposes, I've uploaded a single HTML file, at the moment of this writing is located at https://www.abelperez.info/index.html. You can use any HTML, CSS, Javascript, images files you like.
On way of uploading files to a S3 bucket is by using the console, like we've done all the other operations, select the bucket, and using Upload and Create folder buttons you can recreate your website directory tree. There are better ways to upload files, for example, using the command line or the Rest API.
Your bucket content should look like this
Let's test it
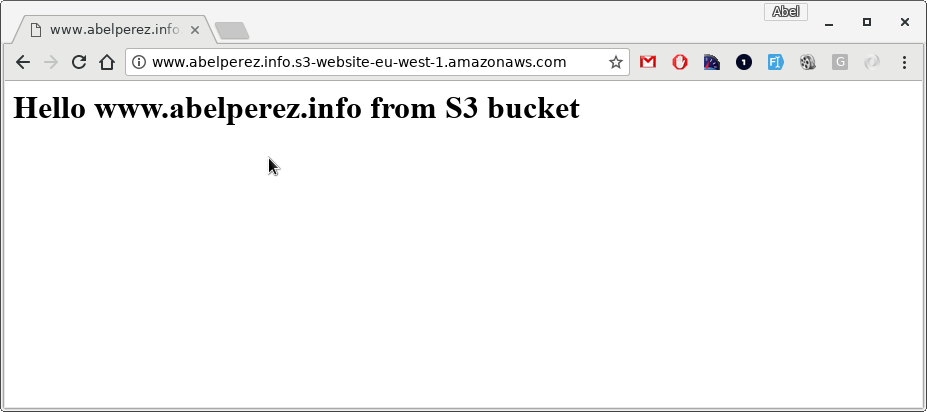
To test all this, it's actually very simple, let's take the HTTP endpoint from earlier and paste in the browser http://www.abelperez.info.s3-website-eu-west-1.amazonaws.com
Your browser content should display this
For full AWS documentation about this topic, see here
No comments:
Post a Comment