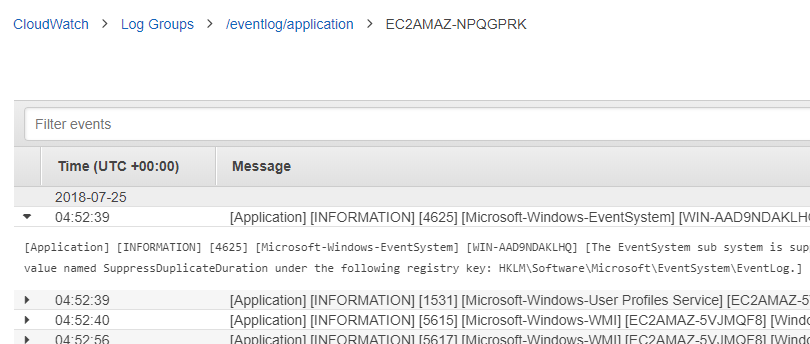
I came across this issue while chasing the infamous “[ warn] [engine] failed to flush chunk” in fluent-bit connected to Elasticsearch. For some context, I'm using Amazon EKS to run my workloads and I use fluent-bit to parse the logs and push them to Elasticsearch so I can query them later on using Kibana.
The first step in this investigation was to set "Trace_Error On" in [OUTPUT] section as part of the fluent-bit configuration, a config map in this instance.
What is the problem ?
[2021/10/07 11:03:51] [ warn] [engine] failed to flush chunk '1-1633604630.
197484999.flb', retry in 11 seconds: task_id=29, input=tail.0 > output=es.0
(out_id=0)
[2021/10/07 11:03:52] [error] [output:es:es.0] error: Output
{
"create": {
"_index": "fluent-bit-000135",
"_type": "_doc",
"_id": "qQZsWnwBkg-cCPSefqtj",
"status": 400,
"error": {
"type": "mapper_parsing_exception",
"reason": "failed to parse field [log_processed.Properties.
StatusCode] of type [long] in document with id 'qQZsWnwBkg-cCPSefqtj'.
Preview of field's value: 'Unauthorized'",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "For input string: \"Unauthorized\""
}
}
}
},
... more logs, removed for brevity ...
This essentially means that the field "log_processed.Properties.StatusCode" was initially mapped (automatically in my case) as "long" and therefore it won't allow the current value "Unauthorized" due to it not being able to parse that as a long value. It's probably my mistake initially not having mapped explictily to a "text" value instead, I could've avoided this situation. But I didn't and here we are.
What is the solution ?
Basically, you need to let Elasticsearch know about the data types in your indexes. A common pattern when working with Elasticearch and Kibana is to creata a State management policy to automatically rolls over your data to a new index and eventually delete old data to avoid disk space to run too low. This requires to have index templates in place so Elasticsearch knows how to create new indexes when the time comes to roll over.
I already use a policy that deletes indices older than 14 days and rolls over after either 1 day or 1 GB of size.
At this point, I'm not terribly bothered about existing data, my priority is to keep new data in good shape. Old data should be reindexed if you want to rescue it and make it available to search on.
What needs to be done is to add a mapping to the index template (assuming you have already one) that contains the property name and type explictily declared.
How to do it ?
Luckily, Kibana gives us a good developer console, that we can run the commands against Elasticsearch endpoints.
Using Kibana Dev Tools Console which you can find under
"https://<your-endpoint>/_plugin/kibana/app/dev_tools#/console"
1 - Update the template
Under "mappings/properties", add a new entry with the property name and type, in this case "log_processed.Properties.StatusCode" of type "text". This will not impact any existing data.
PUT /_index_template/ism_retention_14d
{
"index_patterns": ["fluent-bit-*"],
"template": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date_nanos"
},
"log_processed.Properties.StatusCode": {
"type": "text"
}
}
},
"settings": {
"index.opendistro.index_state_management.rollover_alias":"fluent-bit",
"sort.field": [ "@timestamp"],
"sort.order": [ "desc"]
}
}
}
2- Verify it's updated
This is only to double check that the change has been applied with the correct values for new indexes to be created matching the pattern (fluent-bit-*) in this case.
GET /_index_template/ism_retention_14d
{
"index_templates" : [
{
"name" : "ism_retention_14d",
"index_template" : {
"index_patterns" : [
"fluent-bit-*"
],
"template" : {
"settings" : {
"index" : {
"opendistro" : {
"index_state_management" : {
"rollover_alias" : "fluent-bit"
}
},
"sort" : {
"field" : [
"@timestamp"
],
"order" : [
"desc"
]
}
}
},
"mappings" : {
"properties" : {
"@timestamp" : {
"type" : "date_nanos"
},
"log_processed.Properties.StatusCode" : {
"type" : "text"
}
}
}
},
"composed_of" : [ ]
}
}
]
}
3- Create new index (+1 the current sequence)
Find out which is the latest sequence number in this index parttern (fluent-bit-000135 in this case), add 1 and create a new index with that name (fluent-bit-000136 in this case).
PUT /fluent-bit-000136
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "fluent-bit-000136"
}
4- Verify the mapping is actually in place
Once the index has been created, it should have inherited that mappings from the template updated above.
GET /fluent-bit-000136/_mapping/field/log_processed.Properties.StatusCode
{
"fluent-bit-000136" : {
"mappings" : {
"log_processed.Properties.StatusCode" : {
"full_name" : "log_processed.Properties.StatusCode",
"mapping" : {
"StatusCode" : {
"type" : "text"
}
}
}
}
}
}
5- Update the alias with "is_write_index"
The new index is now ready to start receiving data. To accomplish that, set the "is_write_index" property to true in the new index and to false in the current target index.
POST /_aliases
{
"actions" : [
{ "add" : {
"index" : "fluent-bit-000135",
"alias" : "fluent-bit",
"is_write_index": false
}
},
{ "add" : {
"index" : "fluent-bit-000136",
"alias" : "fluent-bit",
"is_write_index": true
}
}
]
}
6- Verify the aliases are correct
Verify the "is_write_index" property is set appropriately to each index from the previous step.
GET fluent-bit-000135/_alias
{
"fluent-bit-000135" : {
"aliases" : {
"fluent-bit" : {
"is_write_index" : false
}
}
}
}
GET fluent-bit-000136/_alias
{
"fluent-bit-000136" : {
"aliases" : {
"fluent-bit" : {
"is_write_index" : true
}
}
}
}
Conclusion
Following these steps will help you to stop those errors that prevent the logs from being added to Elasticsearch and therefore missing from your queries and potentially from alerts based on that information.
Having state management policies is crucial to achieve a sensible retention policy as well as avoiding creating too large indexes. It also eases the process of updating the template from time to time to keep up with your applications' needs.