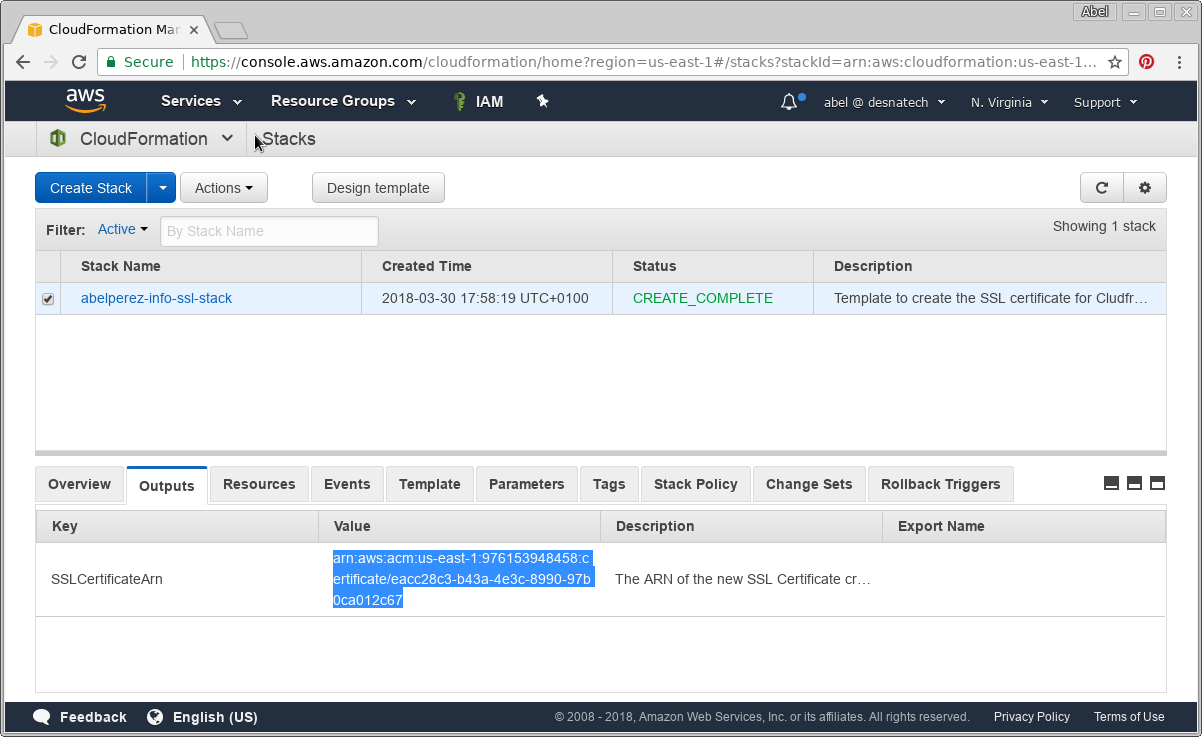
In my previous series I went through the process of creating the cloud resources to host a static website as well as the development pipeline to automate the process from push code in source control to deploy on a S3 bucket.
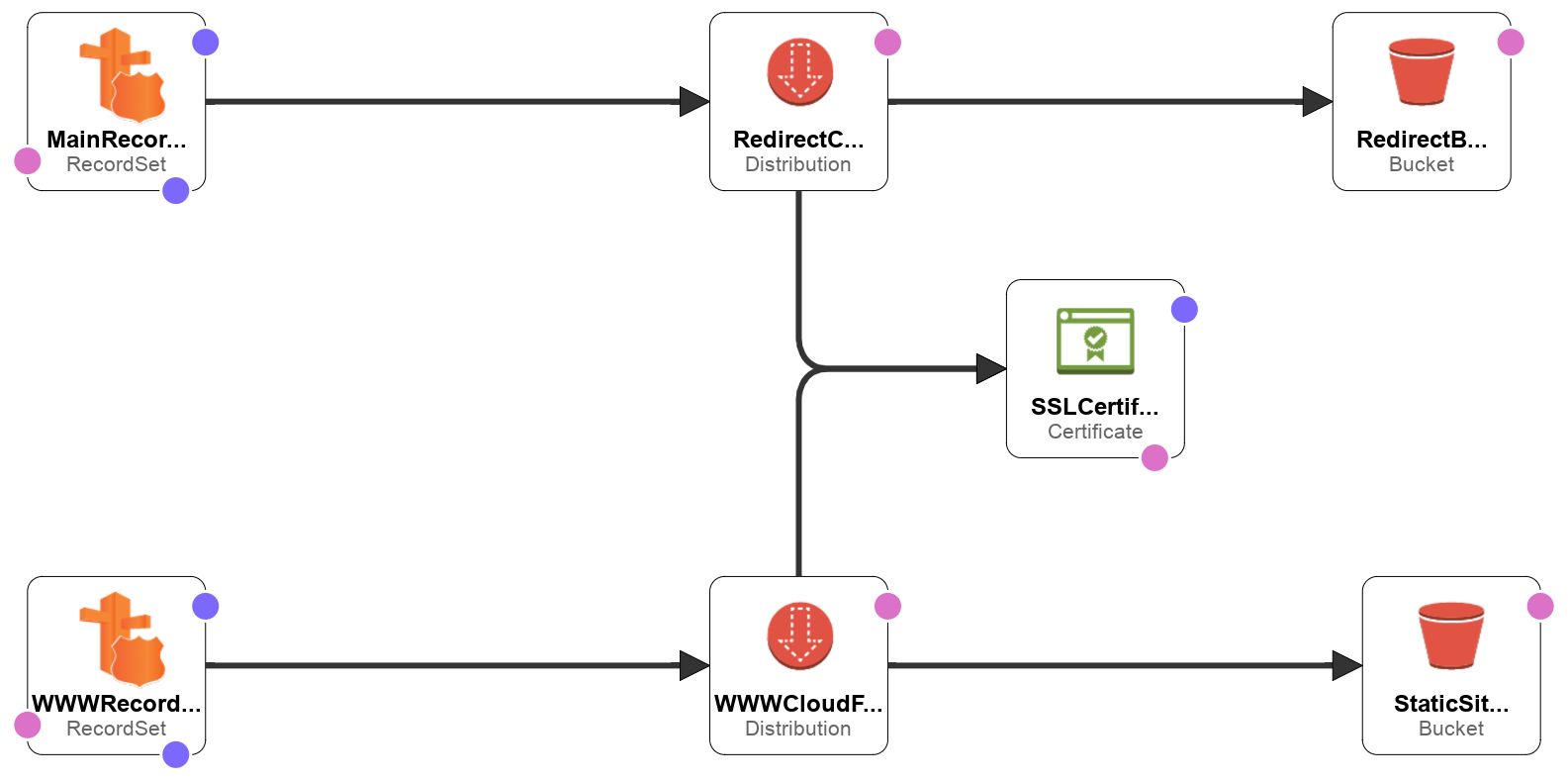
One of the challenges was how to approach the www to non-www redirection, the proposed solution consisted of duplicating the CloudFront distributions and the S3 website buckets in order to get the traffic end to end, the reason why I took this approach was because CloudFront doesn't have (to the best of my knowledge at the time) the ability to issue redirect, instead it just pass traffic to different origins based on configuration.
What is Lamda@Edge ?
Well, I was wrong, there is in fact a way to make CloudFront to issue redirects, it's called Lambda@Edge, a special flavour of Lambda functions that are executed on Edge locations and therefore closer to the end user. It allows a lot more than just issuing HTTP redirects.
In practice this means we can intercept any of the four events that happen when the user request a page to CloudFront and execute our Lambda code.
- After CloudFront receives a request from a viewer (viewer request)
- Before CloudFront forwards the request to the origin (origin request)
- After CloudFront receives the response from the origin (origin response)
- Before CloudFront forwards the response to the viewer (viewer response)
In this post, we're going to leverage Lambda@Edge to create another variation of the same infrastructure by using hooking our Lambda function to Viewer Request event, it will look like this one when finished.
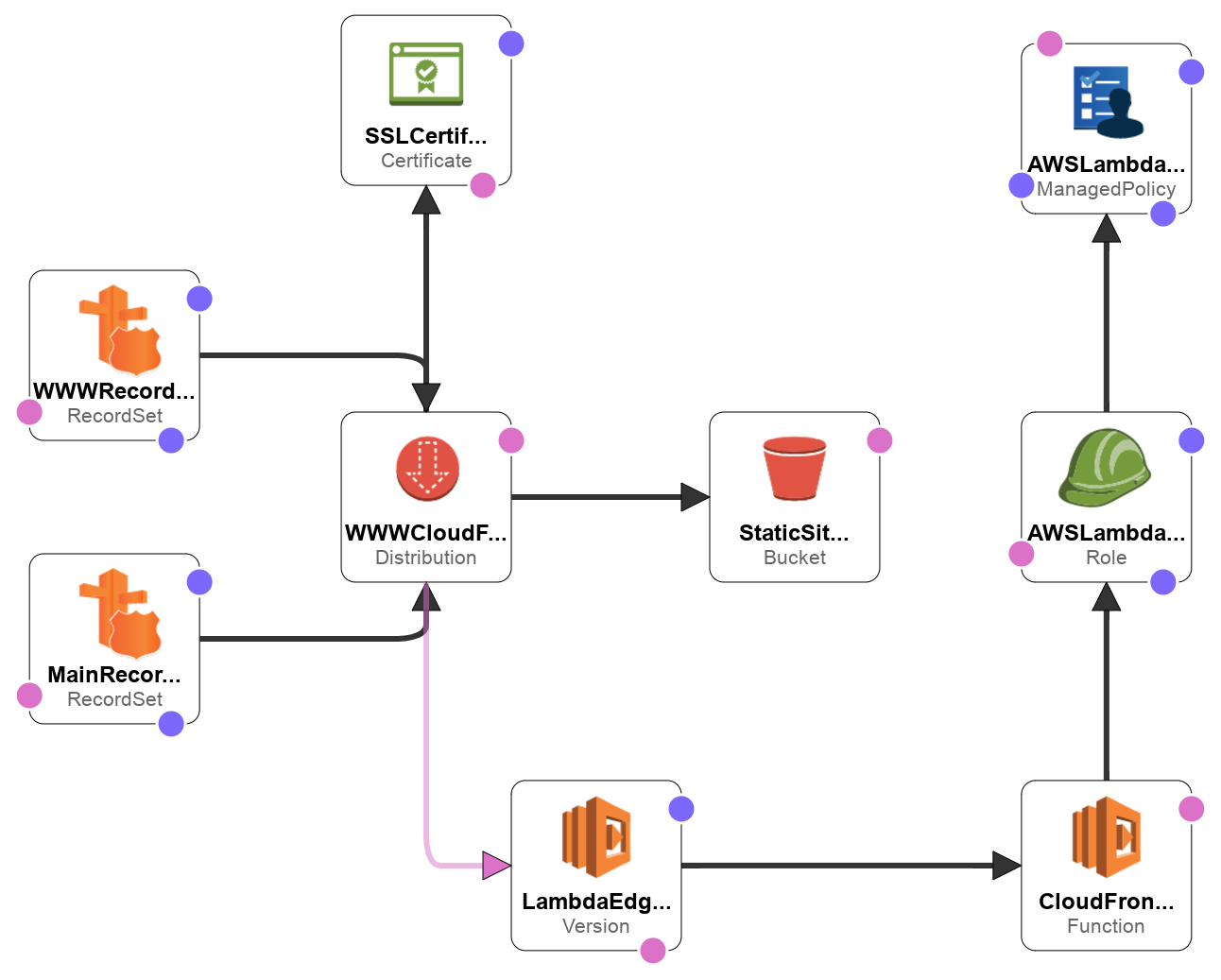
How does it change from previous approach?
This time we still need two Route 53 record sets, because we're still handling both abelperez.info and www.abelperez.info.
We need only one S3 bucket, since redirection will be issued by Lambda@Edge, so no need for Redirection Bucket resource.
We need only one CloudFront distribution as there a single origin, but this time the CloudFront distribution will have two CNAMEs in order to handle both www and non-www. We'll also link the lambda function with the event as part of default cache behaviour.
Finally we need to create a Lambda function to performs the redirection when necessary.
Creating Lambda@Edge function
Creating a Lambda@Edge function is not too far from creating an ordinary Lambda function, but we need to be aware of some limitations (at least at the moment of writing), they need to be created only in N. Virginia (US-East-1) region and the available runtime is NodeJs 6.10.
Following the steps from AWS CloudFront Developer Guide, you can create your own Lambda@Edge function and connect it to a CloudFront distribution. Here are some of my highlights:
- Be aware of the required permissions, telling Lambda to create the role is handy.
- Remove triggers before creating the function as it can take longer to replicate
- You need to publish a version of the function before associating with any trigger.
The code I used is very simple, it only reads host header from the request and verify if it's equal to 'abelperez.info' to send a custom response with a HTTP 301 redirection to www domain host, in any other case, it just let it pass ignoring the request, therefore CloudFront will proceed with the request life cycle.
exports.handler = function(event, context, callback) {
const request = event.Records[0].cf.request;
const headers = request.headers;
const host = headers.host[0].value;
if (host !== 'abelperez.info') {
callback(null, request);
return;
}
const response = {
status: '301',
statusDescription: 'Moved Permanently',
headers: {
location: [{
key: 'Location',
value: 'https://www.abelperez.info',
}],
},
};
callback(null, response);
};
Adding the triggers
Once we have created and published the Lambda fuction, it's time to add the trigger, in this case it's CloudFront and we need to provide the CloudFront distribution Id and select the event type which is viewer-request as stated above.
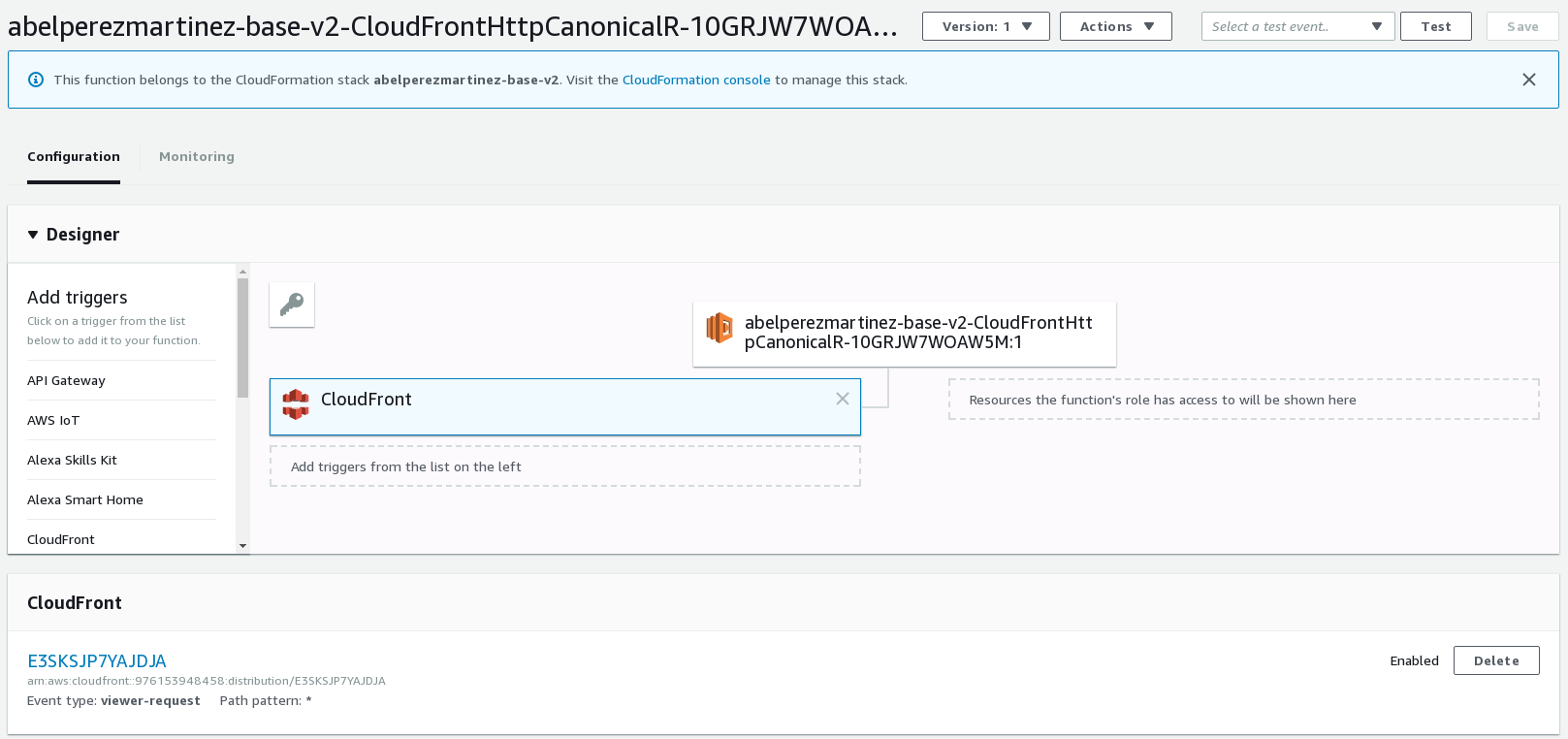
From this point, we've just created a Lambda@Edge function!
Let's test it
The easiest way to test what we've done is to issue a couple of curl commands, one requesting www over HTTPS expecting a HTTP 200 with our HTML and another one request to non-www over HTTP expecting a HTTP 302 with the location pointing to www domain. Here is the output.
abel@ABEL-DESKTOP:~$ curl https://www.abelperez.info <html> <body> <h1>Hello from S3 bucket :) </h1> </body> </html> abel@ABEL-DESKTOP:~$ abel@ABEL-DESKTOP:~$ curl http://abelperez.info <html> <head><title>301 Moved Permanently</title></head> <body bgcolor="white"> <center><h1>301 Moved Permanently</h1></center> <hr><center>CloudFront</center> </body> </html>
An automated version of this can be found at my github repo