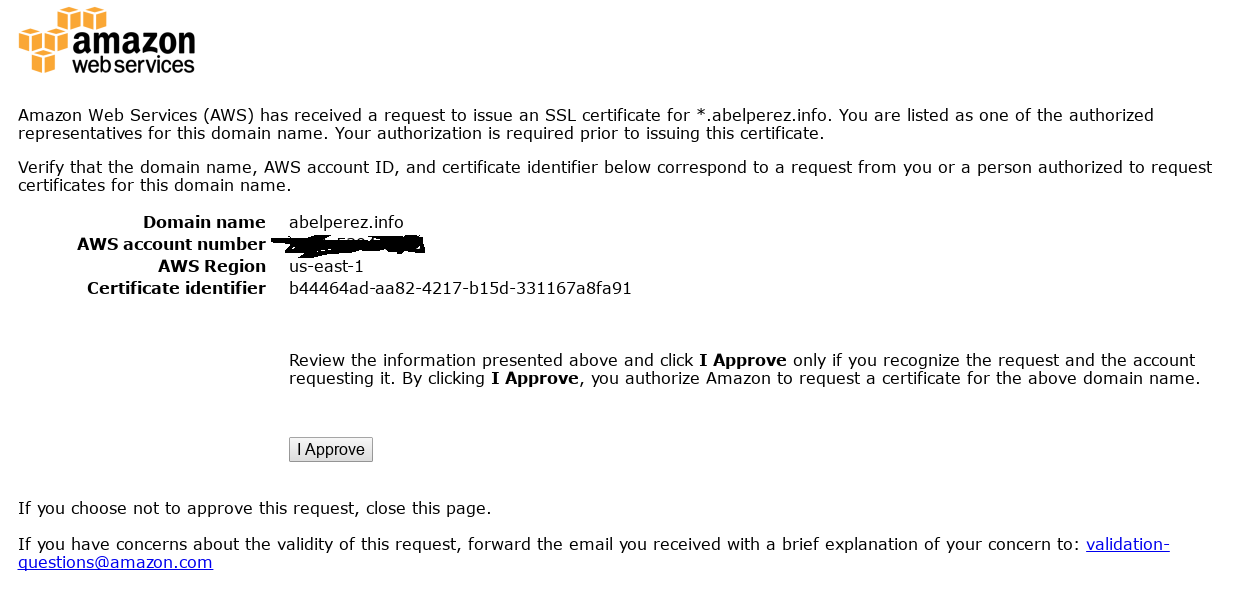
YAML has become a popular format used to describe a wide range of information in a more readable way. Depending on the concrete use case, these files can grow significantly. One example of this is AWS CloudFormation templates which can be written either in JSON or YAML.
Especially when working on Serverless projects, it doesn’t matter if it’s serverless framework, AWS SAM or just pure CloudFormation. The fact is the main file to maintain is (most of the time) a YAML template that grows over time.
I’d like to focus on a more concrete example: a typical serverless microservice architecture consists of a backend database, a function and a HTTP endpoint (i.e DynamoDB, Lambda and API Gateway). It’s also a common practice to use OpenAPI specification aka Swagger to describe the Web API interface.
In this case, when trying to use Lambda integration (either custom or proxy) we can’t use variables or intrinsic functions within the swagger file (we have to hardcode the lambda invocation url including account number and region, apart from the fact that function name might change if using autogenerated by CloudFormation), unless swagger content is inline in the Body property, which makes the file to grow by a great deal.
As of this writing, there are some strategies proposed by AWS to mitigate this problem, I personally find them a bit cumbersome to use on a daily basis:
- AWS::CloudFormation::Stack It adds complexity to the whole process since we have to pass parameters to nested stacks and retrieve outputs from them in order to access information from both parties. The template for the nested stack must be stored on an Amazon S3 bucket, which adds friction to our development workflow while building.
- AWS::Include Transform which is a form of macro hosted by AWS CloudFormation, is simpler than nested stacks but currently it still has some limiations:
- The snippet has to be stored on an Amazon S3 bucket.
- If the snippets change, your stack doesn't automatically pick up those changes.
- It does not currently support using shorthand notations for YAML snippets.
Personally, I prefer a solution where at development time I can split the template in logical parts and then, before deploying it to AWS, compose them in one piece. I like the idea of include partials in specific parts of the parent file.
How to implement this include mechanism ?
YAML provides an extension mechanism named tags, where we can associate a particular data type with a tag (it’s basically a prefix added to a value). In YamlDotNet this is implemented by creating a custom type converter and mapping the new tag with the custom type converter.
IncludeTagConverter (custom type converter)
public class IncludeTagConverter: IYamlTypeConverter
{
public bool Accepts(Type type)
{
return typeof(IncludeTag).IsAssignableFrom(type);
}
public object ReadYaml(IParser parser, Type type)
{
parser.Expect<MappingStart>();
var key = parser.Expect<Scalar>();
var val = parser.Expect<Scalar>();
parser.Expect<MappingEnd>();
if (key.Value != "File")
{
throw new YamlException(key.Start, val.End, "Expected a scalar named 'File'");
}
var input = File.ReadAllText(val.Value);
var data = YamlSerializer.Deserialize(input);
return data;
}
public void WriteYaml(IEmitter emitter, object value, Type type)
{
}
}
IncludeTag class
public class IncludeTag
{
public string File { get; set; }
}
In this case we are indicating that IncludeTagConverter class should be used if the desiralization mechanism needs to deserialize an object of type IncludeTag. At the end of ReadYaml method, we call a helper class that starts deserialization process again with the content of the “included file”.
YamlSerializer helper class
public class YamlSerializer
{
private const string IncludeTag = "!Include";
public static object Deserialize(string yaml)
{
var reader = new StringReader(yaml);
var deserializer = new DeserializerBuilder()
.WithTypeConverter(new IncludeTagConverter())
.WithTagMapping(IncludeTag, typeof(IncludeTag))
.Build();
var data = deserializer.Deserialize(reader);
return data;
}
public static string Serialize(object data)
{
var serializer = new SerializerBuilder().Build();
var yaml = serializer.Serialize(data);
return yaml;
}
}
In this helper class, we tell the deserializer that we are using a type converter and that it has to map !Include tags to data type of IncludeTag. This way, when it encounters an !Include in the yaml file, it will use our type converter to deserialize the content instead, which in turn, will read whatever file we put the name in File: key and will trigger the deserialization process again, thus, allowing us to execute this at several levels in a recursive way.
How do we compose a yaml ?
Once we have the whole file yaml object in memory, by triggering the deserialization process on the main yaml file, like this:
var data = YamlSerializer.Deserialize(input);
We only need to call Serialize again, and since we converted all the !Include tags into normal maps, sequence or scalars, there’s nothing extra we need to do to serialize it back using the default implementation.
var output = YamlSerializer.Serialize(data);
The output will be the composed file which can be saved and used after that.
Example:
Main yaml file (cloud-api.yaml)
Description: Template to create a serverless web api
Resources:
ApiGatewayRestApi:
Type: AWS::ApiGateway::RestApi
Properties:
Name: Serverless API
Description: Serverless API - Using CloudFormation and Swagger
Body: !Include
File: simple-swagger.yaml
simple-swagger.yaml file
swagger: "2.0"
info:
version: 1.0.0
title: Simple API
description: A simple API to learn how to write OpenAPI Specification
paths:
/persons: !Include
File: persons.yaml
/pets: !Include
File: pets.yaml
persons.yaml file
get:
summary: Gets some persons
description: Returns a list containing all persons.
responses:
200:
description: A list of Person
schema:
type: array
items:
required:
- username
properties:
firstName:
type: string
lastName:
type: string
username:
type: string
pets.yaml file
get:
summary: Gets some pets
description: Returns a list containing all pets.
responses:
200:
description: A list of pets
schema:
type: array
items:
required:
- petname
properties:
petname:
type: string
ownerName:
type: string
breed:
type: string
Final result (composed file)
Description: Template to create a serverless web api
Resources:
ApiGatewayRestApi:
Type: AWS::ApiGateway::RestApi
Properties:
Name: Serverless API
Description: Serverless API - Using CloudFormation and Swagger
Body:
swagger: 2.0
info:
version: 1.0.0
title: Simple API
description: A simple API to learn how to write OpenAPI Specification
paths:
/persons:
get:
summary: Gets some persons
description: Returns a list containing all persons.
responses:
200:
description: A list of Person
schema:
type: array
items:
required:
- username
properties:
firstName:
type: string
lastName:
type: string
username:
type: string
/pets:
get:
summary: Gets some pets
description: Returns a list containing all pets.
responses:
200:
description: A list of pets
schema:
type: array
items:
required:
- petname
properties:
petname:
type: string
ownerName:
type: string
breed:
type: string